“Debes asegurarte de que los datos sean relevantes, limpios y representativos.”
El Procesamiento del Lenguaje Natural (NLP: natural language processing en inglés) es el campo de estudio que se enfoca en la comprensión mediante ordenador del lenguaje humano. Abarca parte de la Ciencia de Datos, Inteligencia Artificial (Aprendizaje Automático) y la lingüística.
En NLP los ordenadores analizan el lenguaje humano, lo interpretan y dan significado para que pueda ser utilizado de manera práctica. Usando NLP podemos hacer tareas como el resumen automático de textos, traducción de idiomas, extracción de relaciones, análisis de sentimiento, reconocimiento del habla y clasificación de artículos por temáticas.
Los modelos de PNL pueden realizar tareas como reconocimiento de voz, traducción automática, análisis de sentimientos, resumen de texto, entre otros.
Pero ¿cómo se entrena a estos modelos para que comprendan y generen un lenguaje natural?
La capacitación de modelos para comprender y generar lenguaje natural es un proceso fascinante y multidimensional que requiere una cuidadosa planificación y ejecución. Antes de adentrarnos en los pasos concretos involucrados en este proceso, es esencial comprender la complejidad y la importancia de cada etapa. Desde la selección adecuada de datos hasta la implementación y evaluación del modelo final, cada paso juega un papel fundamental.
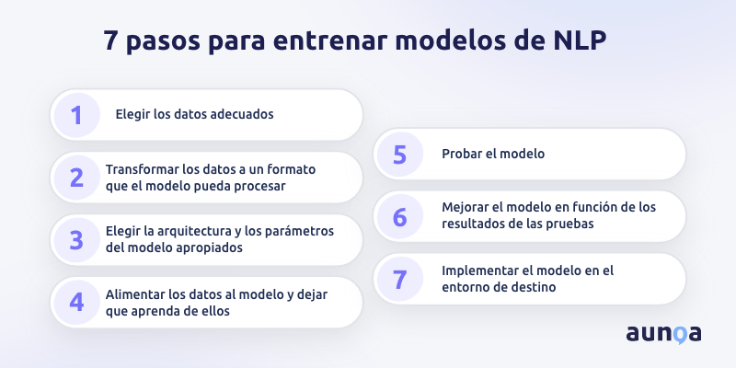
Paso 1:
El primer paso para entrenar y probar modelos de PNL es elegir los datos adecuados. Dependiendo de la tarea que vayamos a realizar, es posible que necesitemos diferentes tipos de datos, como texto, voz, imágenes o videos. También hay que tener en cuenta la calidad, la cantidad, la diversidad y la disponibilidad de los datos.
Por ejemplo, si quieres crear un modelo de análisis de sentimientos, necesitarías un conjunto de datos grande y equilibrado de texto con etiquetas que indiquen las emociones u opiniones expresadas. También debes asegurarte de que los datos sean relevantes, limpios y representativos.
Paso 2:
El siguiente paso es transformar los datos a un formato que el modelo pueda procesar y comprender. Esto puede implicar varias técnicas, como tokenización, normalización, lematización, derivación, eliminación de palabras vacías, eliminación de puntuación, corrección ortográfica y más. Estas técnicas ayudan a reducir el ruido, la complejidad y la ambigüedad de los datos y a extraer las características y significados esenciales.
Paso 3:
El tercer paso es elegir la arquitectura y los parámetros del modelo apropiados para la tarea y los datos. Existen muchos tipos de modelos de PNL, como modelos basados en reglas, modelos estadísticos, modelos neuronales o modelos híbridos. Cada modelo tiene sus propias ventajas y desventajas, y es necesario considerar factores como la precisión, la velocidad, la escalabilidad, la interpretabilidad y la generalización.

Paso 4:
El cuarto paso es alimentar los datos al modelo y dejar que aprenda de ellos. Esto puede implicar dividir los datos en conjuntos de entrenamiento, validación y prueba, y aplicar diferentes algoritmos de aprendizaje, como aprendizaje supervisado, aprendizaje no supervisado, aprendizaje semisupervisado o aprendizaje por refuerzo.
El entrenamiento implica alimentar los datos al modelo y actualizar los parámetros del modelo mediante un algoritmo de aprendizaje. También debes supervisar el rendimiento del modelo en el conjunto de validación mediante una métrica, como la precisión para determinar cuándo detener o ajustar el proceso de entrenamiento.
Paso 5:
El quinto paso es probar el modelo. Las pruebas implican aplicar el modelo a datos no vistos y comparar las predicciones del modelo con las etiquetas asignadas. También es necesario analizar los errores del modelo e identificar los puntos fuertes y débiles del modelo. Por ejemplo, si deseas crear un modelo de traducción automática, debes probar el modelo en diferentes idiomas y comprobar la calidad y la fluidez de las traducciones.
Paso 6:
El sexto paso es mejorar el modelo en función de los resultados de las pruebas. Ajustar y mejorar el modelo en función de los resultados y la retroalimentación del paso anterior.
Paso 7:
El último paso del entrenamiento del modelo de PNL es implementar el modelo en el entorno de destino y utilizarlo para el propósito previsto. Esto puede implicar exportar el modelo a un archivo o servicio en la nube, integrarlo con una aplicación o plataforma, o exponerlo como una API o un servicio web. También debes asegurarte de que el modelo sea seguro, de confianza, escalable y mantenible, y que cumpla con los estándares éticos y legales. Es posible que también necesites actualizar o volver a entrenar el modelo periódicamente según los comentarios de los usuarios o los datos.